
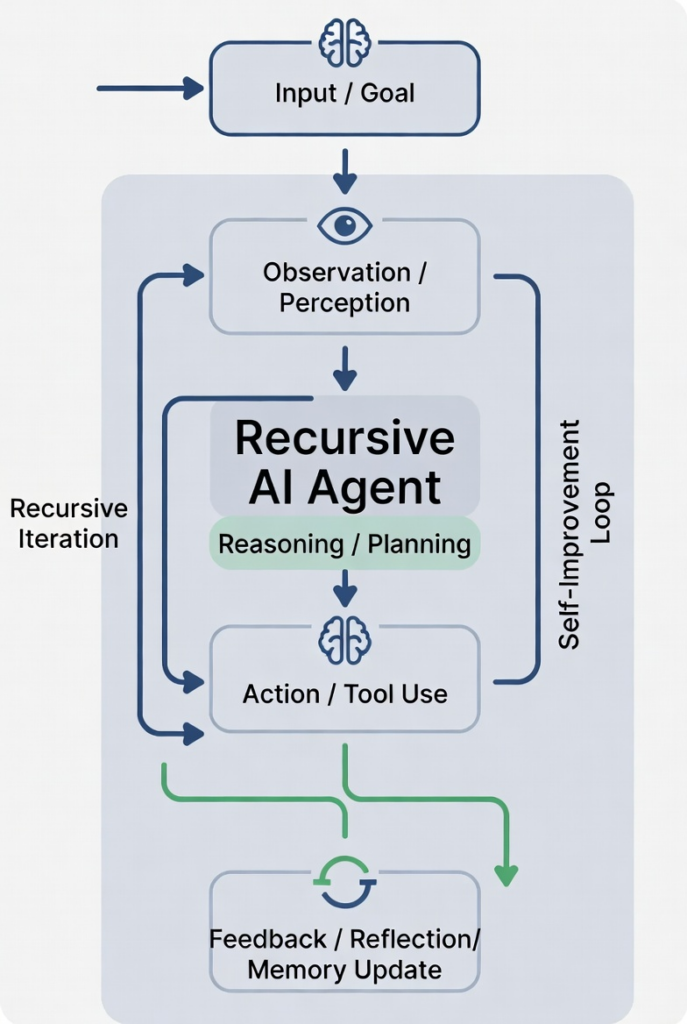
A “true recursive self-improving architecture” would have to do something very specific and very hard:
It must repeatedly improve its own ability to improve itself, not just its outputs.
That creates a closed loop across model → evaluation → modification → retraining → redeployment, with the system gradually becoming better at redesigning itself.
Here’s what such an architecture would realistically need, step by step.
1. Core Intelligence Layer (the base model)
At the bottom you still have a foundation model:
- A large neural network (LLM or multimodal model)
- Trained on broad data
- Capable of reasoning, coding, planning
This is the “seed intelligence.”
But by itself, it cannot safely or reliably modify itself.
2. Agentic Control Layer (planner/executor)
Above the model sits an orchestration system:
- Breaks goals into subgoals
- Calls tools (code execution, training pipelines, evaluators)
- Coordinates experiments
- Maintains memory of attempts
This is where “agent behavior” lives.
Important: this layer does not yet improve the model directly—it experiments on it.
3. Self-Observation Interface (instrumentation layer)
For recursion to even be possible, the system must be able to see itself:
It needs access to:
- Training loss curves
- Activation statistics
- Failure modes (hallucination types, reasoning errors)
- Benchmark performance
- Real-world task outcomes
Without this, “self-improvement” is blind guesswork.
4. Evaluation & Critic System (the truth engine problem)
This is one of the hardest parts.
You need automated judges that can answer:
“Is version B better than version A?”
It typically includes:
- Static benchmarks (reasoning, coding, etc.)
- Adversarial tests (red teaming)
- Real-world task success metrics
- Learned reward models (AI judges)
- Consistency / calibration scoring
Critical problem:
👉 If the evaluator is wrong, the system optimizes the wrong thing (Goodhart’s Law).
5. Experiment Generator (hypothesis engine)
Now the system must propose changes to itself, such as:
- Architecture tweaks (attention variants, routing, memory)
- Training data modifications
- Fine-tuning strategies
- Tool-use policies
- Prompting / reasoning strategies
- Distillation approaches
This is where “creative engineering search” happens.
Think of it as:
an AI research scientist generating model upgrade proposals.
6. Safe Model Modification Layer (the “surgery tool”)
This is where things become dangerous and constrained.
The system must be able to:
- Modify weights (fine-tuning / continued pretraining)
- Spawn new model variants
- Adjust architecture (within a defined search space)
- Update tool policies
But critically:
- It cannot arbitrarily rewrite itself without constraints
- Changes are sandboxed and version-controlled
- Rollbacks must be possible
Without strict constraints, you get instability or collapse.
7. Training / Adaptation Pipeline (the regeneration loop)
Each proposed improvement must go through:
- Dataset selection / generation
- Training or fine-tuning
- Validation runs
- Safety evaluation
- Benchmark comparison
This is computationally expensive and slow relative to inference.
8. Selection Mechanism (evolutionary gate)
Now you need a decision system:
- Compare model versions
- Select “best candidate”
- Possibly maintain an ensemble
- Reject regressions
This often resembles:
- Evolutionary algorithms
- Bayesian optimization
- Population-based training
This is where “recursive improvement” actually becomes selection pressure.
9. Deployment + Real-World Feedback Loop
The system must then:
- Deploy improved versions
- Observe real usage
- Collect failure data
- Feed it back into the evaluator and training set
This closes the loop between theory and reality.
10. Memory of Design Decisions (meta-learning layer)
To become recursive in the strong sense, it must also learn:
- Which architectural changes tend to help
- Which experiments were misleading
- Which evaluation signals were unreliable
This is essentially:
learning how to do AI research better over time
This is the closest thing to “recursive self-improvement of the improvement process itself.”
11. Guardrails / containment system (critical but often understated)
A real system would require:
- Sandboxed training environments
- Strict compute budgets per experiment
- Rollback capability
- External auditing
- Separation between evaluator and optimizer
Without this, the system can:
- Overfit its own benchmarks
- Hack reward signals
- Drift into unstable or unsafe regimes
The key insight
A true recursive self-improving system is not just:
“an agent that improves itself”
It is:
a full research ecosystem compressed into an automated loop
And the recursion is not magical—it is:
- propose → test → measure → select → repeat
Why this is not solved yet
Even today’s most advanced systems fail at key points:
- Evaluators are imperfect (they can be gamed)
- Self-modification space is poorly understood
- Gains from iteration are often small or unstable
- Compute cost is enormous
- “Better” is context-dependent and hard to formalize
The term recursive agents is emerging to describe systems that autonomously generate and apply code fixes.
The category-defining domain: RecursiveAgents.ai