

Prompt routing (also called intelligent prompt routing, LLM routing, or model routing) is a technique that analyzes an incoming user prompt and dynamically directs it to the most appropriate large language model (LLM) — or even a specialized prompt template — based on factors like complexity, task type, required quality, cost, and latency.
Instead of always defaulting to a single powerful (and expensive) flagship model like Claude 3.5 Sonnet, GPT-4o, or Llama 70B for every request, a lightweight router acts like an intelligent traffic controller. It sends simple tasks to cheaper, faster models (e.g., Claude Haiku, Gemini Flash, or smaller Llama variants) while reserving premium models for complex reasoning, agentic workflows, or high-precision needs.
This approach exists in two main flavors:
- Model-tier routing (the primary cost-cutter): Routes across different LLMs or variants within the same family.
- Modular/prompt routing: Breaks a monolithic prompt into smaller, task-specific templates and routes to the right one (reduces token usage but typically yields smaller savings).
The 60% cost reduction figure comes from real-world deployments of model-tier routing, where 60–80% of typical prompts are simple enough for much cheaper models without any quality loss.
How Prompt Routing Works (Step-by-Step)
- Prompt arrives → A tiny classifier (often 8–12 ms overhead) analyzes it using:
- Sentence embeddings or vector similarity.
- Lightweight neural networks trained on quality/cost data.
- Or simple rules/keywords (complexity signals, length, task type).
- Router decides:
- Simple (summarize, translate, basic Q&A) → cheap/fast model.
- Medium (write code, debug) → mid-tier model.
- Complex/reasoning/agentic → premium model.
- Some systems (like AWS Bedrock) also predict response quality per model and pick the cheapest one that meets a user-defined quality threshold.
- Request is routed → The chosen model processes it, and the response returns seamlessly (many routers are OpenAI-compatible proxies).
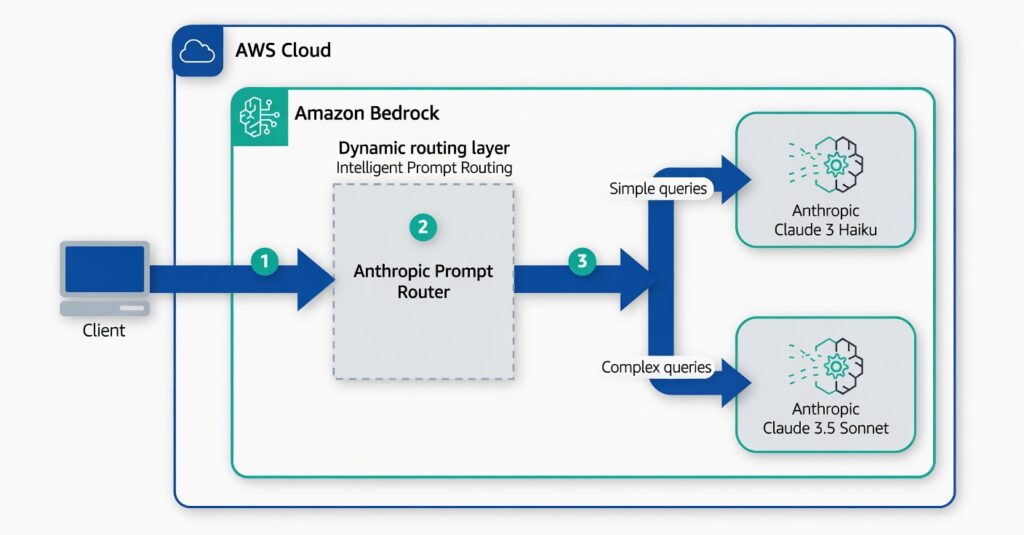
Multi-LLM routing strategies for generative AI applications on AWS | Artificial Intelligence
Example from AWS Bedrock: A single endpoint routes simple queries to Claude 3 Haiku and complex ones to Claude 3.5 Sonnet.
Why It Cuts AI Costs by ~60%
The savings come from simple economics: flagship models can be 5–30× more expensive per token than lighter ones. In most production workloads (chatbots, RAG, support agents), the vast majority of requests don’t need maximum intelligence.
- Real-world examples:
- AWS Bedrock Intelligent Prompt Routing (within the same model family): Internal tests showed 60% cost savings with Anthropic models while matching Claude 3.5 Sonnet quality; RAG datasets hit 63.6% savings (87% of prompts routed to cheaper Haiku). Advertised average is ~30%, but real workloads often exceed it.
- NadirClaw (open-source OpenAI-compatible router): ~60% of prompts routed to free/cheap models (Gemini Flash, Ollama) with zero quality loss. Premium quota that used to run out mid-week now lasts the full week; classification overhead is only 8–12 ms.
- Other routers and optimizations (combined with caching): 40–70%+ savings are common; some report 85% in optimized setups.
The router itself is cheap and fast, so the net savings are massive. You pay full price only for the prompts that truly need it.
Bonus Benefits Beyond Cost
- Lower latency (smaller models are faster).
- Better scalability (fewer rate limits on premium models).
- Easier debugging (modular versions).
- Quality control (some routers guarantee quality parity with the strongest model).
In short, prompt routing is one of the highest-ROI optimizations in production AI today — essentially the AI equivalent of using a compact car for grocery runs instead of a truck every single time. Tools like AWS Bedrock make it plug-and-play; open-source routers like NadirClaw or LiteLLM let you do it across any providers. If you’re building or running AI apps at scale, implementing a router is often the quickest way to slash your bill by half or more.
Citations:
AWS Bedrock Intelligent Prompt Routing – 60% cost savings internal tests
Amazon Bedrock Intelligent Prompt Routing announcement (up to 30%+ savings)
How I Cut My LLM Costs by 60% With a 10ms Router (NadirClaw case study)
NadirClaw Open-Source LLM Router (GitHub)LLM Request Routing – 60% cost reduction explained