
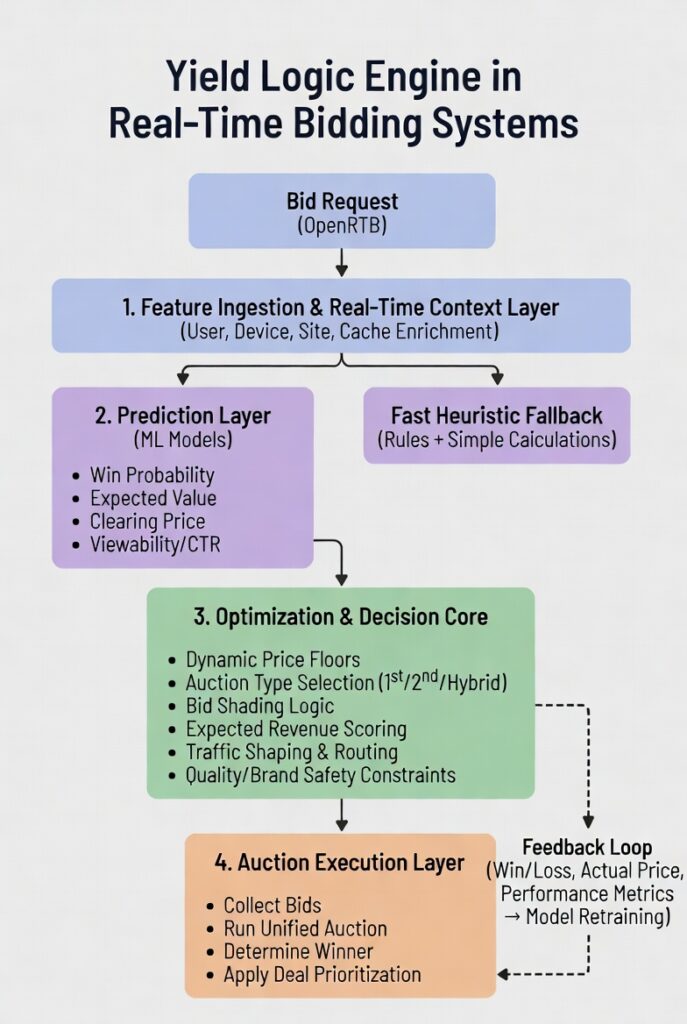
In the high-stakes world of real-time bidding (RTB), every impression is an auction that must resolve in under 100–300 milliseconds. Publishers want to maximize revenue per impression (yield), while the entire ecosystem fights extreme latency, noisy data, and complex auction dynamics.
At the heart of modern Supply-Side Platforms (SSPs) — and increasingly sophisticated Demand-Side Platforms (DSPs) — sits the yield logic engine. This is not a simple price floor setter or basic auction router. It is a real-time decision engine that orchestrates prediction, optimization, auction mechanics, and trade-offs under strict latency budgets.
For infra engineers and early-stage AdTech startups, understanding how a production-grade yield logic engine is architected can mean the difference between winning auctions consistently or timing out and losing revenue.
The Core Role: Turning Impressions into Optimized Revenue
A yield logic engine’s primary job is to maximize expected revenue (or eCPM) for each bid request while respecting publisher policies, brand safety, and technical constraints. On the sell side, this often means:
- Dynamically setting or adjusting price floors
- Deciding auction type (first-price, second-price, or hybrid)
- Routing or shaping traffic to demand sources
- Applying bid shading logic or deal prioritization
- Running unified auctions that blend OpenRTB bids with direct deals, header bidding waterfalls, or server-side mediation
On the buy side (DSPs), similar logic determines whether to bid at all, what price to submit, which creative to attach, and how to pace budgets — all while predicting the win probability and post-win value of the impression.
The engine is fundamentally a high-throughput, low-latency decision system that combines rule-based logic, machine learning predictions, and real-time optimization.
Key Components of a Yield Logic Engine
- Feature Ingestion & Real-Time Context Layer Every bid request arrives with OpenRTB fields: user data, device, site/app context, geo, etc. A good engine enriches this instantly using cached user profiles (often from high-performance stores like Aerospike, Redis, or key-value databases optimized for sub-millisecond reads). Features include historical performance signals, consent status, viewability predictions, and contextual embeddings. Latency here is critical — enrichment must happen in <5–10ms.
- Prediction Layer (The ML Brain) This is where modern yield engines differentiate. Models predict:
- Win probability at different bid prices (essential for bid shading and optimal bidding)
- Expected value (e.g., predicted CTR, CVR, or ROAS for DSPs; expected clearing price for SSPs)
- Fill rate or timeout risk for specific demand partners
- Optimization & Decision Core The engine combines predictions with business rules:
- Dynamic floor pricing (e.g., based on predicted competition or historical clearing prices)
- Auction dynamics simulation (what happens in a first-price vs. second-price environment?)
- Multi-source unification (blending RTB bids, PMPs, preferred deals)
- Yield vs. quality trade-offs (e.g., blocking low-quality demand even if it pays slightly more)
- Auction Execution Layer Once decisions are made, the engine routes bid requests intelligently (traffic shaping to avoid overwhelming DSPs with irrelevant QPS), collects responses, runs the final auction, and determines the winner. In header bidding or server-side setups, it may orchestrate parallel calls with adaptive timeouts.
- Feedback & Learning Loop Post-auction data (win/loss, actual clearing price, performance metrics) feeds back into models for continuous improvement. This requires robust logging, feature stores, and offline/online training pipelines without disrupting real-time serving.
Auction Dynamics the Engine Must Handle
RTB auctions are no longer pure second-price. First-price auctions dominate in many exchanges, leading to widespread bid shading strategies — bidders submit less than their true valuation to avoid overpaying. A yield engine on the SSP side must anticipate this behavior to set floors that extract maximum revenue without deterring participation.
Dynamics also include:
- Bid density management: Filtering low-value requests to maintain healthy competition.
- Multi-auction competition: When the same impression runs through multiple exchanges or wrappers.
- Game-theoretic elements: Bidders adapt strategies based on observed market behavior, sometimes modeled with approaches like minority game theory for segmentation of time slots or inventory types.
The engine must simulate or approximate these dynamics quickly — often using pre-computed look-up tables or lightweight simulators rather than full game-theoretic solving per request.
The domain name, YieldLogic.ai is for sale, visit YieldLogic.ai
Latency + Prediction: The Eternal Trade-Off
This is the hardest engineering challenge.
Typical RTB budgets:
- Total end-to-end: 100–300ms
- DSP/SSP processing: often <80–100ms after network time
- Google and major exchanges enforce strict tmax timeouts and throttle slow responders
Every added prediction or rule increases latency. Smart architectures address this through:
- Parallel execution of independent components (e.g., feature fetch + simple rules in parallel with heavy ML inference)
- Adaptive timeouts and fallback logic (if ML inference is slow, fall back to simpler heuristic models)
- Geographic peering and edge computing to cut network hops
- Pre-warming and caching of hot paths
- Model distillation or multi-stage ranking (cheap model first to filter, expensive model only on promising impressions)
Teams optimizing RTB latency often report that shaving even 10–20ms can meaningfully improve win rates and fill rates.
Infrastructure choices matter enormously: in-memory databases for profiles, GPU/TPU-accelerated inference where volume justifies it, or highly optimized CPU serving for cost-efficiency. At scale (millions of QPS), everything from data locality to garbage collection tuning becomes yield-critical.
What This Looks Like in Practice for Startups
For a DSP/SSP startup, building a yield logic engine from scratch means prioritizing:
- A modular, observable architecture (metrics on every stage: enrichment time, prediction latency, decision time, auction time)
- Graceful degradation: always have a fast heuristic path
- Experimentation framework for A/B testing new floor logic or models without risking revenue
- Cost-aware design (inference can get expensive at high volume)
Many successful systems start with rule-heavy logic and gradually layer in ML predictions as data and infra mature. Others go “agentic” or AI-native early, using predictive pre-positioning to reduce real-time work.
The best engines feel invisible to end users but deliver measurable lifts — higher eCPMs for publishers, better ROI for advertisers, and fewer timeouts for everyone.
Why It Matters Now
As programmatic matures, competition intensifies around supply path optimization, contextual signals (post-cookie), and AI-driven decisioning. Yield logic engines are evolving from static optimizers into adaptive, predictive systems that treat every auction as a micro-optimization problem.
For infra engineers and founders building the next generation of DSPs or SSPs, the yield logic engine is the competitive moat. Get the architecture right — balancing sophisticated prediction with ruthless latency discipline — and you can deliver superior yield in a market where milliseconds and percentages decide winners.
The engine doesn’t just run auctions. It thinks about them in real time, under pressure, at planetary scale.
The domain name, YieldLogic.ai is for sale, click YieldLogic.ai